
动态学习环境中迁移专家场景的PlipPlop算法
中文题目:动态学习环境中迁移专家场景的PlipPlop算法
论文题目:The PlipPlop algorithm for migrating expert scenarios in dynamic learning environments
录用期刊/会议:CCC2025 (CAA A类会议)
录用时间:2025.1.2
作者列表:
1)宋宇 中国免费靠逼视频(北京)人工智能学院 自动化系 教师
2)周佳佳 中国免费靠逼视频(北京)人工智能学院 控制科学与工程 研18级
3)代思怡 中国免费靠逼视频(北京)人工智能学院 控制科学与工程 研23级
4)刘建伟 中国免费靠逼视频(北京)人工智能学院 自动化系 教师
摘要:
首先,我们选择相对熵损失函数作为自适应权值动态更新工具,用于获取迁移专家学习场景的后悔上界。 其次,参考在线触发器算法的讨论,推导了如何自适应地动态调整学习速率。我们也得到了学习率的上界。 最后将学习率的上界转化为后悔函数的上界,讨论了如何在后悔函数上得到一个更小的上界,实现超参数的自适应调整。
主要内容:
定理:假定,
,
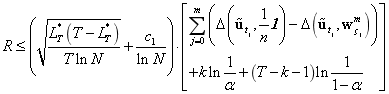
这里,
Theorem 10: 假定, 权重
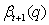 服从:
服从:
这里
比较序列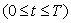 具有k次迁移:
具有k次迁移:
权值更新算法
具有下列后悔上界:
这里,
结论:
本文将2014年De Rooij等人提出的在线触发器算法应用于迁移专家,讨论了学习率的优化和调整对学习效果的影响。迁移专家场景在不同的区域有不同的模型,所以我们首先使用混合权重更新公式来讨论在线学习中的迁移场景,通过混合前一刻的权重,很大程度上可以减少迁移带来的损失,从而得到一个新的误差上界。混合权重更新公式可以解决稀疏复杂模型的问题,该方法对许多真实数据集非常有效。同时,考虑到在迁移场景中,很难在不同的学习阶段给出一个最优的学习速率,在线触发器算法可以通过调整相同概率分布产生的数据或不同概率分布产生的数据的学习率来获得更好的学习效果,因此,触发器算法为本文的讨论提供了完整的理论基础。我们讨论了损失函数和近似损失函数之间的差来设置学习率的切换条件,学习率可以实时地选择和切换,以实现迁移专家场景中学习率的调整。实验结果进一步验证了将触发器算法应用于迁移专家在线学习,可以获得更小的后悔上界。
作者简介:
刘建伟,教师。