
一种在物联网设备上进行高效深度学习推理的方法
中文题目:一种在物联网设备上进行高效深度学习推理的方法
论文题目:Efficient Deep Learning Inference on IoT Devices
录用期刊/会议:2025 European Conference on Computer Systems (CCF A Poster)
原文链接: http://2025.eurosys.org/accepted-posters.html#pagetop
录用时间:2025年2月24日
作者列表:
1) 刘志卓 中国免费靠逼视频(北京)人工智能学院 先进科学与工程计算专业 博 22
2) 刘 民 中国免费靠逼视频(北京)人工智能学院 计算机科学与技术专业 硕 21
3) 徐朝农 中国免费靠逼视频(北京)人工智能学院 计算机系教师
5) 李 超 之江实验室
文章简介:
深度神经网络(DNNs)在多个领域取得了显著成果。由于其较高的内存和计算需求,DNN 通常部署在数据并行加速器上。近年来,一些研究人员尝试在资源受限的物联网(IoT)设备上部署 DNNs。然而,IoT 设备通常具有较低的计算性能和有限的内存容量,这导致了模型部署的高资源需求与 IoT 设备有限资源之间的矛盾。为了解决这一矛盾,量化被认为是一种有效的方案。然而,现有的量化研究仅在精度与推理延迟或内存占用之间达到了平衡,导致生成的模型在IoT上的部署效率仍然较低。
另一方面,DNN 库被广泛应用于 IoT 设备,以提升 DNN 推理的吞吐量和计算效率。CMix-NN和 CMSIS-NN 是专为 MCU 设计的低精度线性代数核,旨在部署量化神经网络。这些内核能够高效并行计算 8-bit 操作数,但对低于 8-bit 的操作数支持不够理想。TVM 采用bit-serial计算方法部分解决了低 8-bit 操作数的计算问题,但无法扩展至基于 ARM Cortex-M 的 MCU。因此,如何设计一种策略将量化模型部署在所有IoT设备上成为挑战。
本文的主要内容如下:
针对资源受限的物联网设备上深度学习模型的高效部署问题,本文提出了一种结合高效量化(RLQuant)与轻量级低精度推理引擎(LiteEngine)的框架MCUQ。首先,RLQuant通过双层优化策略搜索最优量化方案,其中上层利用强化学习确定最佳比特宽度,下层使用SGD优化量化步长。随后,LiteEngine采用通用操作数打包技术,以降低内存占用并加速推理。LiteEngine反馈推理延迟、内存占用和精度信息,以优化RLQuant的量化策略。相比其它推理引擎,MCUQ可减少1.5-2.8倍的内存占用,并加速推理1.6-3.0倍,同时保持精度几乎不变。
摘要:
在基于微控制器单元(MCU)的资源受限物联网(IoT)设备上部署深度学习模型极具吸引力,但由于计算能力和内存资源的限制,面临着重大挑战。为了在 MCU 上高效部署深度学习模型,本文提出了一种新型框架 MCUQ,该框架结合了高效量化方法(RLQuant)和轻量级低精度推理引擎(LiteEngine)。RLQuant 通过求解双层优化问题来寻找最优量化策略,其中上层优化问题利用强化学习搜索最优比特宽度,而下层优化问题使用随机梯度下降(SGD)进行量化步骤的优化。在每次强化学习迭代后,LiteEngine 通过通用操作数打包技术执行推理,从而降低内存需求并加速模型推理。LiteEngine 与 RLQuant 紧密结合,通过反馈推理延迟、内存使用和精度等信息,优化 RLQuant 的量化策略。与 CMix-NN、CMSIS-NN 和 TinyEngine 相比,MCUQ 能够减少 1.5-2.8 倍的内存使用,并加速推理 1.6-3.0 倍。MCUQ 是首个在商用 MCU 上实现高效模型推理且几乎无精度损失的推理框架。
设计与实现:
本文提出了 MCUQ,它由 RLQuant 和 LiteEngine 共同设计。RLQuant 采用强化学习(RL)同时为网络的每一层寻找最优的比特宽度和量化步长,而 LiteEngine 作为 RL 的一部分,为智能体提供直接反馈,包括精度、推理延迟和内存占用情况。LiteEngine 能够充分利用 MCU 中有限的资源,避免内存和计算资源的浪费,并为 RLQuant 的量化策略搜索提供更大的搜索空间。凭借更大的搜索空间,RLQuant 更有可能找到精度损失可以忽略不计的量化模型。
RLQuant 利用强化学习(RL)智能体来预测𝓑,并使用梯度下降来学习 𝓢。如图所示,RLQuant 首先使用智能体预测模型 𝓜的 𝓑ₑ。接下来,SGD 优化器学习模型的最优𝓢ₑ。最后,LiteEngine 优化
的乘法相关计算和内存调度,以测量最优推理延迟和内存使用情况。此外,在一个 episode 的第 t 个时间步中,智能体根据当前观察状态
确定第 t 层的量化比特宽度,即激活值和权重的比特宽度。该观察状态包括当前层的通道数、MACs(乘加运算次数)或卷积核大小等信息。
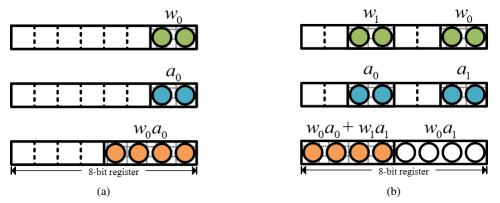
操作数打包的本质在于,通过将多个低精度(低 8-bit)的操作数打包到一个更宽的寄存器中,并使用这两个打包后的寄存器执行常规乘法运算,从而实现低精度点积计算。如图a所示,常规乘法运算一次只能处理一对操作数。而图b展示了操作数打包技术的应用,通过执行一次 8-bit 乘法,可以同时计算两对 2-bit 操作数的点积。其计算结果表示为:
然而,由于该结果超出了目标寄存器的最大存储值,高位项 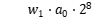 发生溢出,最终目标寄存器仅存储值:
发生溢出,最终目标寄存器仅存储值: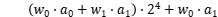 。从公式中非常容易地观察到,24的系数
。从公式中非常容易地观察到,24的系数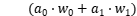 是两对低精度操作数点乘运算结果。因此,可以通过一个高精度通用乘法指令实现多个低精度操作数的点乘运算。接下来,可以在目标寄存器上实施低成本的掩码和移位操作以获得最终的点乘结果。本文将该打包技术推广到不同的权重值位宽和激活值位宽策略,并推导出防止潜在溢出所需满足的条件。
是两对低精度操作数点乘运算结果。因此,可以通过一个高精度通用乘法指令实现多个低精度操作数的点乘运算。接下来,可以在目标寄存器上实施低成本的掩码和移位操作以获得最终的点乘结果。本文将该打包技术推广到不同的权重值位宽和激活值位宽策略,并推导出防止潜在溢出所需满足的条件。
实验结果及分析:
本文对在四种不同的卷积神经网络上进行了评估。下图显示,与 CMSIS-NN、CMix-NN 和 TinyEngine 相比,LiteEngine 实现了高达3倍的推理加速。这一显著的加速主要归功于 LiteEngine 采用的通用操作数打包方法。此外,算法与系统的协同设计使得对执行模型的控制更加精确,从而实现了针对 RLQuant 量化模型的优化内存调度和代码生成。
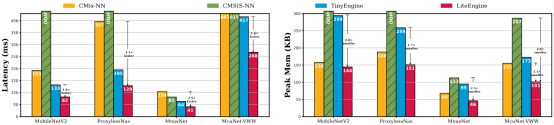
LiteEngine 通过消除运行时解释延迟,并避免为存储模型元数据分配额外内存,使其能够处理高精度模型。因此,LiteEngine 提高了内存使用效率,相比 CMSIS-NN 其内存占用减少了2.8倍。
结论:
我们提出 MCUQ 框架,结合 RLQuant 进行高效量化和 LiteEngine 进行优化的低精度推理。RLQuant 与 LiteEngine 协同设计,扩展搜索空间,使模型能够高效地部署到 MCU上。实验表明,该方法可减少高达 2.8 倍的内存占用,并加速推理至 3.0 倍。
作者简介:
徐朝农,中国免费靠逼视频(北京)人工智能学院教师,主要研究领域为边缘智能、嵌入式系统、无线网络。